Чтобы понять рекурсию, надо понять рекурсию...
Итерация в программировании — в широком смысле — организация обработки данных, при которой действия повторяются многократно, не приводя при этом к вызовам самих себя (в отличие от
рекурсии). В узком смысле — один шаг циклического процесса обработки данных.
Часто итерационные алгоритмы на текущем шаге (итерации) используют вычисленный на предыдущих шагах результат такой же операции или действия. Одним из примеров таких вычислений служат вычисления рекуррентных соотношений.
Простым примером величины, вычисляемой с помощью рекуррентных соотношений, является факториал:
\(N!=1 \cdot 2 \cdot 3 \cdot \ ... \ \cdot N\)
Вычисление значения на каждом шаге (итерация) это
\(N=N \cdot i\) . При вычислении значения
\(N\), мы берем уже сохраненное значение
\(N\).
Факториал числа можно также описать с помощью
рекуррентной формулы:
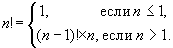
Можно заметить, что это описание является ни чем иным как рекурсивной функцией.
Здесь первая строка (
\(n <= 1\)) — это базовый случай (условие окончания рекурсии), а вторая строка - переход к следующему шагу.
| Рекурсивная фнкция вычисления факториала будет выглядеть следующим образом |
Сравните алгоритм нахождения факториала обычным не рекурсивным способом |
int Factorial(int n){
if (n > 1)
return n * Factorial(n - 1);
else return 1;
}
|
x = 1;
for (i = 2; i <= n; i++)
x = x * i;
printf("%d",x);
|
Следует понимать, что вызов функций влечет за собой некоторые дополнительные накладные расходы, поэтому не рекурсивный вариант вычисления факториала будет несколько более быстрым.
Вывод: там, где можно написать программу простым итерационным алгоритмом, без рекурсии, то надо писать без рекурсии. Но все таки существует большой класс задач где вычислительный процесс реализуется только рекурсией.
С другой стороны - рекурсивные алгоритмы чаще всего более понятны.