Представление строк в памяти компьютера
Любой набор данных в оперативной памяти компьютера должен храниться в виде двоичного числа. Это относится и к строкам, которые состоят из символов (буквы, знаки препинания и т.д.). Когда символ сохраняется в памяти, он сначала преобразуется в цифровой код. И затем этот цифровой код сохраняется в памяти как двоичное число.
За прошедшие годы для представления символов в памяти компьютера были разработаны различные схемы кодирования. Исторически самой важной из этих схем кодирования является схема кодирования ASCII (American Standard Code for Information Interchange – американский стандартный код обмена информацией).
Таблица символов ASCII
ASCII представляет собой набор из 128 цифровых кодов, которые обозначают английские буквы, различные знаки препинания и другие символы. Например, код ASCII для прописной английской буквы «А» (латинской) равняется 65. Когда на компьютерной клавиатуре вы набираете букву «А» в верхнем регистре, в памяти сохраняется число 65 (как двоичное число, разумеется).

Код ASCII для английской «В» в верхнем регистре равняется 66, для «С» в верхнем регистре – 67 и т. д. На один символ в ASCII отводится ровно 7 бит.
 Аббревиатура ASCll произносится «аски».
Аббревиатура ASCll произносится «аски».
ASCII table
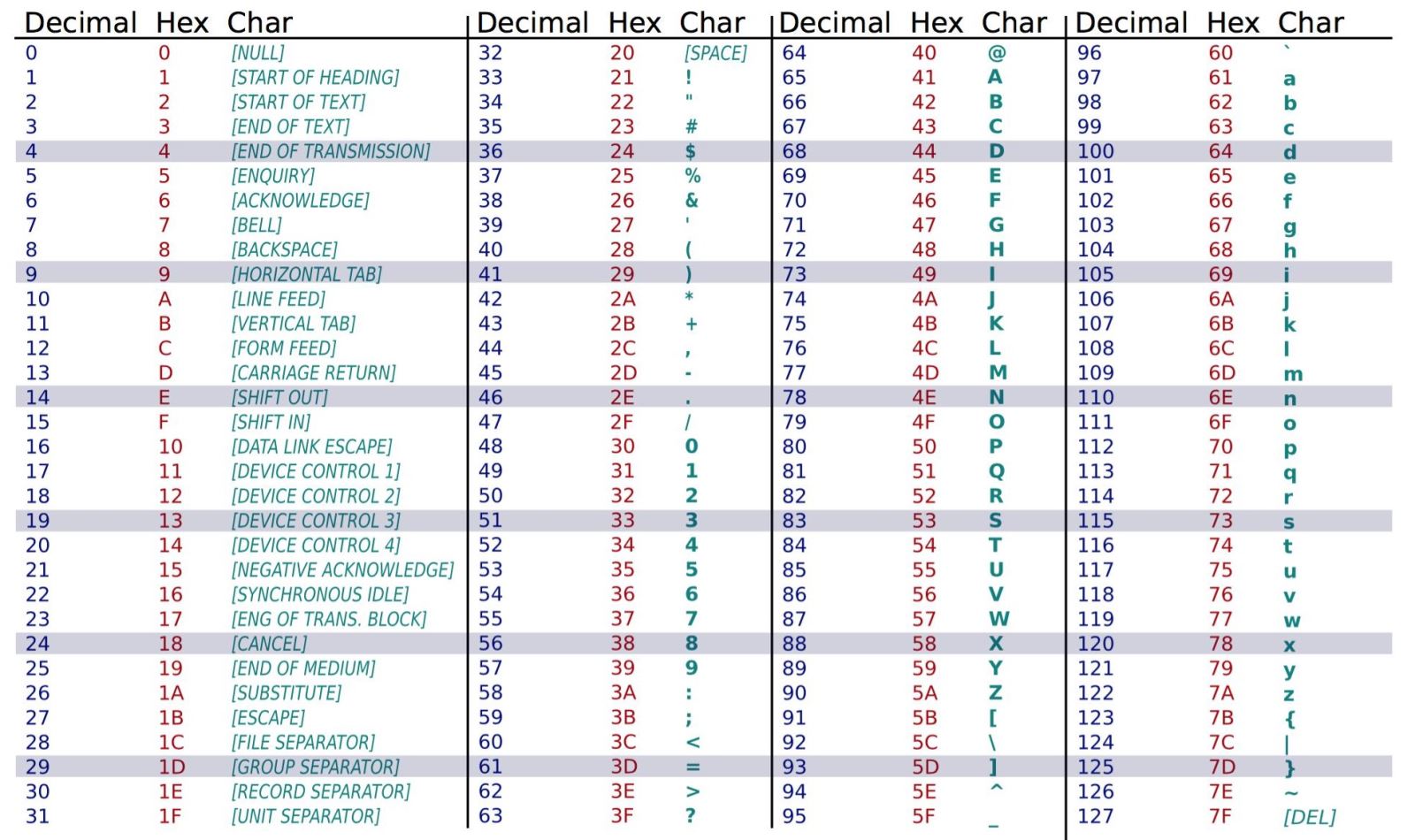
Набор символов ASCII был разработан в начале 1960-х годов и в конечном счете принят почти всеми производителями компьютеров. Однако схема кодирования ASCII имеет ограничения, потому что она определяет коды только для 128 символов. Для того чтобы это исправить, в начале 1990-х годов был разработан набор символов Юникода (Unicode). Это широкая схема кодирования, совместимая с ASCII, которая может также представлять символы многих языков мира. Сегодня Юникод быстро становится стандартным набором символов, используемым в компьютерной индустрии.
Таблица символов Unicode
Таблица символов Юникод представляет собой набор цифровых символов, которые включают в себя знаки почти всех письменных языков мира. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода». Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотации.
Стандарт состоит из двух основных частей: универсального набора символов и семейства кодировок (Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа. Семейство кодировок определяет способы преобразования кодов символов для хранения на компьютере и передачи.
В Юникод все время добавляются новые символы, а сам размер этой таблицы не ограничен и будет только расти, поэтому сейчас при хранении в памяти одного юникод-символа может потребоваться от 1 до 8 байт. Отсутствие ограничений привело к тому, что стали появляться символы на все случаи жизни.
В Python строки хранятся в виде последовательности юникод символов.
Примечания
Примечание 1. Официальный сайт таблицы символов Unicode.
Примечание 2. Юникод — это не кодировка. Это именно таблица символов. То, как символы с соответствующими кодами будут храниться в памяти компьютера, зависит от конкретной кодировки, базирующейся на Юникоде, например UTF-8.
Примечание 3. Первые 128 кодов таблицы символов Unicode совпадают с ASCII.