Каждый сотрудник компании «Blake Technologies» пользуется специализированным приложением для мгновенного обмена сообщениями, которое носит название «Blake Messenger». Все сотрудники любят это приложение и пользуются им постоянно. Однако не всё так гладко, как хотелось бы. Многим не хватает очень важной функции — поиска по сообщениям. Поэтому было принято решение реализовать эту функцию в следующей версии мессенджера. К сожалению, из-за особенностей хранения сообщений разработчикам столкнулись с некоторыми проблемами...
Все сообщения в приложении представляют собой строки, состоящие только из строчных букв английского алфавита. В целях снижения нагрузки эти строки передаются и хранятся в сжатом виде. Алгоритм сжатия работает следующим образом: строка s разбивается на n последовательных блоков одинаковых букв. Такую часть можно описать парой (li, сi), где li — длина i-й части, а ci — символ, который используется в i-й части. Таким образом, строку s можно записать в сжатом виде парами 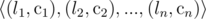 .
.
Требуется написать программу, которая по заданным сжатым строкам t и s находит все вхождения строки s в строку t. Разработчики понимают, что таких вхождений может быть очень много, поэтому требуется вывести только количество различных позиций вхождений строки s в строку t. Напомним, что позиция p является позицией вхождения строки s в строку t тогда и только тогда, когда tptp + 1...tp + |s| - 1 = s, где ti — i-й символ строки t.
Обратите внимание на то, что, к примеру, строка "aaaa" может быть сжата несколькими способами: 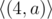 ,
, 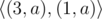 ,
, 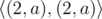 ...
...
Примечание
В первом примере t = "aaabbccccaaacc", a s = "aabbc". Строка s входит в строку t только в одной позиции p = 2.
Во втором тесте t = "aaabbbbbbaaaaaaacccceeeeeeeeaa", а s = "aaa". Строка s входит в строку t в следующих позициях: p = 1, p = 10, p = 11, p = 12, p = 13, p = 14.